
Feed discovery and Flock
I spend a lot of time thinking about bringing feed reading to a wider audience. A sobering statistic is that the overwhelming majority of web users, upwards of 95%, have no knowledge of the technology or how it can help them stay on top of content they're interested in.
One of the larger obstacles to adoption has been the lack of a consistent, user friendly mechanism for identifying and subscribing to feeds on the web. A widely adopted auto-discovery markup convention and browser integration have improved the experience dramatically. Publishers now have a mechanism by which they can provide the user with notification that feeds are available. However, in practice, current implementations can give confusing results. This is due largely to the LINK tag convention suffering from the classic invisible metadata problem: data that is out of sight easily falls into disrepair. Broken links, duplicate feeds, and invalid or poorly written titles are common in LINK tags and lead to ambiguous results like this:

There are two distinct feeds associated with this web page, and no good way to differentiate them using the metadata provided in the LINK tags. This is inconvenient for the advanced user and downright confusing for the novice.
Flock attempts to improve this situation by fetching and parsing feeds mentioned in LINK tags in the background as you browse. This lets us validate the feeds, get authoritative rather than secondhand metadata, and gives us the opportunity to use more advanced deduping techniques to provide the user with a more relevant selection:

The end result is a more consistent feed subscription experience on the wild, wild web.
July 31, 2006 @ 9:00 PM | Permalink | Category: Technology | Comments (1)
Feed reading in Flock
After several weeks of all-out cranking, our feed reading workflow in Flock has really come to life. Here's a peek at the My News feature:
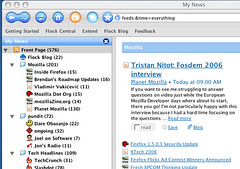
May 2, 2006 @ 4:39 PM | Permalink | Category: Technology | Comments (2)
all I want for christmas is two terabytes of storage
Now and then I look through all the files on my powerbook and remember that I've always been lucky. I've never had a catastrophic disk failure or inadvertently formatted the wrong volume losing years of irreplaceable data. I have partial backups here and there, but they'd provide only a small cushion. It's time to come up with better system, while I'm still a statistical outlier.
In an ideal world I'd have every last byte of my digital existence versioned and mirrored across geographically distributed data centers. Failing that, I think a ReadyNAS from Infrant Technologies might do nicely. I need a mass storage device with redundancy and plenty of room to grow, but quiet and small enough to stick under the couch. Something I can throw multiple backup disk images at and still have scratch space left over for when the powerbook is down to its last gig. ReadyNAS seems to fit the bill. Anyone out there already using one?
December 11, 2005 @ 11:22 AM | Permalink | Category: Technology | Comments (2)
press for Sage
Sage gets a generous amount of attention from the blogosphere, but there's still something special about seeing your work mentioned in print. We get favorable reviews by Om Malik in a Business 2.0 article, and more recently in Firefox Secrets by Cheah Chu Yeow.
July 4, 2005 @ 11:16 PM | Permalink | Category: Technology | Comments (1)
automata
An interesting link from a William Gibson post. A renaissance art form lives on in Switzerland. Dating back to da Vinci, the European fascination with automata created what could be thought of as the first robots, man's fledgling attempt to mimic natural processes.
I've always been interested in the work of Jacques de Vaucanson, whose creations were some of the most intricate. They haven't survived the ages, but Vaucanson's duck and flute player are thought to represent the height of the automata craze.
Today, what was once cutting edge tech has become anachronistic curiosity. Which leads me back to a favorite Neuromancer passage:
The most unusual thing Jimmy had managed to score on his swing through the archipelago was a head, an intricately worked bust, cloisonné over platinum, studded with seedpearls and lapis. Smith, sighing, had put down his pocket microscope and advised Jimmy to melt the thing down. It was contemporary, not an antique, and had no value to the collector. Jimmy laughed. The thing was a computer terminal, he said. It could talk. And not in a synth-voice, but with a beautiful arrangement of gears and miniature organ pipes. It was a baroque thing for anyone to have constructed, a perverse thing, because synth-voice chips cost next to nothing. It was a curiosity. Smith jacked the head into his computer and listened as the melodious, inhuman voice piped the figures of last year's tax return.
March 22, 2005 @ 12:30 PM | Permalink | Category: Technology | Comments (0)
new connections
In rambling around the web recently, I came across the new work of an old favorite author whose thoughts I've always found interesting. As a student years ago, the Connections column by James Burke was probably the sole reason I maintained my subscription to Scientific American. It was always the first thing I flipped to in a new issue, and often the last. In it, he traced the influence of people, events, and scientific thought through time to uncover interesting relationships. A continuation of his work on the famous BBC series with the same name, the column may not have been as scientifically rigorous as the articles that accompanied it, but its sheer scope and untethered historical insight made it simply addictive.
It seems that James has an up and coming project known as Knowledge Web that aims to enable his tangential style of discovery in an online learning context. As he explains in a related interview, the web-based tool would allow the user to visualize and explore a network of interdisciplinary connections that Burke and other researchers have compiled over time. Think of it as Friendster with renaissance thinkers, monarchs, and modern scientific heavyweights for profiles.
February 14, 2005 @ 12:44 AM | Permalink | Category: Technology | Comments (0)
Sage 1.3 in the wild
We released Sage 1.3 today. Time to show everyone what we've been working on over the last two months. This release introduces several important features and a pile of new locales. Some user reactions:
What a great little tool. So clean, lean and fast. Bloody marvellous!
This is the best integration of RSS and a browser i've found!
I don't need RSS support in Thunderbird or the Fox's Live Bookmarks or an external Feed reader anymore. Sage rocks.
November 17, 2004 @ 3:04 PM | Permalink | Category: Technology | Comments (3)
Firefox as a platform
Om Malik has an article in the November issue of Business 2.0 that sheds light on Firefox as a platform for application development. It's good to see this aspect of the Mozilla project getting attention. Mozilla technology is more than a means of experiencing today's web, it's a big step towards creating the extensible rich client of tomorrow's web.
In a recent interview, Ben Goodger had a few comments on the road ahead for Firefox as an application framework:
Some of our goals in the next 12-18 months include improvements to the core rendering technology to make web developers' lives easier and also "productizing" the application development platform if you will, so that people will be able to download a "XULrunner" (with Firefox, probably) and then run other compact applications on it.
If the push to neatly package and spread Firefox to end users is the first phase of adoption, the second will be the formalization and popularization of its development environment. Applications drive platform adoption. Right now, the excellent web browsing experience you get out of the box is driving adoption, this is the first application. Soon we'll see the development of third party XUL apps that, in and of themselves, can provide the incentive needed to download and install Firefox.
October 22, 2004 @ 12:18 PM | Permalink | Category: Technology | Comments (0)
The Gilmore Gang on feeds in Firefox
The Gilmore Gang touched on the importance of feed aggregation in the Mozilla product line during last week's installment. Persistent feed storage and offline reading capability are mentioned frequently as key features. Considering the addition of RSS support in Thunderbird, Steve Gilmore asked:
Are we seeing the rise of a cross platform RSS aggregator that's essentially available for free from an open source group?
Just as there was a time when people were willing to pay for web browsers, aggregators are now getting their dollars from the early adopters. In time, the core feature set will be commoditized by FOSS projects and commercial offerings will be relegated to advanced users and special applications of the syndication standards. Fanning the flames of the RSS ubiquity push was Apple's announcement of Safari RSS at its WWDC in June. With user expectations raised, Firefox seems naked without a comparable offering. Scott Rafer, CEO of Feedster, remarked:
The Firefox guys have been trying to not upset the variety of Firefox plugins that are decent RSS aggregators, and they're going to have to give up and pick one at some point.. and at some point not very long in the future I would suspect.
Forumzilla gets mentioned as a candidate for integration. Haven't explored Forumzilla yet, but I understand that it's a Thunderbird extension allowing feeds to be manipulated though the mail reading interface, and that it's the basis for the newly added feed aggregation in Thunderbird itself.
Integrating with the email client does offer efficiency in the form of workflow reuse, but I see the browser as being the ideal spot to land feed reading functionality. The overlap between activities is just too strong to ignore. Sage is an attempt to leverage this overlap, and provide the simplicity required for mass adoption while offering enough features to woo power users. A big and increasingly important step for us will be to provide persistent storage of feed items, opening the door to another level of functionality.
October 4, 2004 @ 8:50 PM | Permalink | Category: Technology | Comments (2)
Sage gets hicksdesigned
When Jon Hicks of Hicksdesign puts together a new look for your feed reader, you take notes. Jon is the pixel master behind the Firefox and Thunderbird icons and an outspoken web standards guru. He writes:
..something that's attracted me back to using Firefox in the last few weeks has been the Sage RSS Reader extension. With a little tweaking to make it look more like an OSX'y, I now have what feels like my ideal Browser/RSS Reader combination.
Jon goes on to provide step-by-step instructions for Sage users looking to make their own visual mods. This is one of the benefits of working with the Mozilla platform.. End User Development. When the barriers to patching an application are unzip and notepad, everyone's a developer. We have a whole group of users poking, prodding, tweaking, and enhancing Sage for their own benefit. Not every mod has broad enough appeal to be incorporated back into the releases, but many do, and all offer insight into use habits.
September 29, 2004 @ 7:56 PM | Permalink | Category: Technology | Comments (0)
my Powerbook gets a new disk
My TiBook DVI was down to the last few bytes of its OEM 40GB Travelstar 80GN drive, so I spent the morning swapping it out for a shiny new 80GB Travelstar 5K80. With a little guidance from the Powerbook G4 Hard Drive Upgrade Guide, I was able to quickly crack open the case, pull out the 80GN and pop in the 5K80. Apple used Torx size 8 fasteners to attach the internal and external hardware, so I had to scrounge around for the right driver bit, other than that, there were no surprises. I slid the 80GN into a slick Macally enclosure, jacked it into the FireWire port, and was booting externally off the old disk in no time.
I was then faced with the challenge of moving my bootable UFS file system from the old disk to an 80GB partition on the new one. I found that Carbon Copy Cloner is a popular tool for Mac disk migration, as it's wise to the resource fork meta data on HFS volumes (the default OS X file system format). Unfortunately it doesn't seem to play nice with UFS, so I kept searching for a solution. Eventually I noticed that OS X's Disk Utility provides disk migration support through it's Restore feature, so I gave it a shot and after around 2 hours of transfer time I had a working copy of my volume on the new disk. I found that creating a bootable image of another disk requires that you select Disk Utility's 'Erase Destination' option in the Restore dialog, this forces a block level transfer as opposed to a file level copy. Without selecting this option I was left with a complete copy of the original, but was unable to select it as the startup disk in System Preferences.
So ends the upgrade saga. Now, not only do I have twice the internal storage in a device the size of half a pack of cigarettes, I've got a larger than expected speedup from the new disk's 5400rpm rotational speed and 8MB cache. Here's to the hard disk industry giving Moore's Law a run for its money.
Note: for those interested in OS X internals, Amit Singh has a section on the Mac boot sequence in his excellent article What is Mac OS X? at kernelthread.com.
September 25, 2004 @ 2:53 PM | Permalink | Category: Technology | Comments (0)
the deal with Live Bookmarks
Live Bookmarks, the new RSS functionality in Firefox, has taken a beating over the last few days. Ben Gooder explains what the goals were for their first stab at RSS in the browser and where they're going with it:
[Live Bookmarks] were never intended to be an answer to the power RSS readers or a comprehensive solution to hardcore RSS/news junkies. ... Firefox's RSS capabilities are designed to expose as much of RSS to regular people as makes sense for light news reading/dynamic content.
...and to this end, it's a good start. I can't help but feel that expectations have been set unrealistically high by more involved implementations in Opera and upcoming Safari RSS. Does Firefox need an integrated heavyweight aggregator if it has an excellent extension mechanism?
September 21, 2004 @ 8:00 PM | Permalink | Category: Technology | Comments (0)
info glut
How long does it take you to work through your feed list? When time's short, those with long lists end up dropping packets during their daily cram. Shyam is looking for local authority analysis and ranking of his feed items to give him a hand:
I want something that does the ranking only from the piece of the pie that I consider important. I want a link or a button on my aggregator which, on clicking, will give me the day's most talked about link or topic.
On a large enough feed list, this might produce interesting results.
September 21, 2004 @ 2:31 AM | Permalink | Category: Technology | Comments (0)
feed discovery, the blogosphere, and Sage
Feed discovery is becoming a hot topic with Sage as we move toward our next release. This feels like uncharted territory and I want to try and highlight some of the options and their tradeoffs.
Discovery is an important component of the aggregator usability equation and an significant opportunity for Sage as its browser integration gives us the ability to do this well. The goal here is to allow users to find and subscribe to new feeds in the most effortless manner possible. I'm going to suggest that there are two complimentary approaches to feed discovery, a lightweight and a heavyweight technique.
At this point in the game, doing feed discovery is something of a black art. There is an accepted method for explicitly associating feeds with HTML documents, but it has yet to spread to the far reaches of the blogosphere and there are a good number of sites that don't make use of it. This is where discovery gets tricky. Without an explicit feed declaration, the only option is to scan through any links present in the HTML document trying to determine which of those might be pointing to a valid feed. There is no feed URL naming convention, so these links can look like anything. Sometimes they're obvious, sometimes they're indistinguishable from other links in the document.
The heavyweight approach is to cover all the bases by checking for explicit feed declarations as well as scan the document identifying feed links in the case that there are no explicit feeds. This is what happens in Sage when you click the 'Discover Feeds' icon. All potential links are probed, meta data is collected for those that turn out to be valid feeds, and the results are ranked by relevance and displayed to the user. The benefit to this approach is the quality of the output, if there's a feed to be found, we'll probably get it. The downside is that it's expensive. It takes network bandwidth and CPU cycles to probe the links in a document and this means you won't get instant results. It also means it would be difficult to perform automatically in the background as the user browses.
The lightweight approach doesn't scan the document body for links to probe, but looks only in the <head> section for explicit feed declarations. If these are found, great, you've got some URL's that probably lead to valid feeds and enough meta data for the user to choose between them. This method is inexpensive and can quickly be done at the users request or in the background as they browse from page to page a la Firefox 1.0 Livemarks and Safari RSS. The downside is that it will come up empty handed on any site that doesn't explicitly list its feeds.
For now, I think the answer may be to make use of both methods, a lightweight discovery process running in the background during regular browsing, and a heavyweight catch-all mechanism available at the user's request. Lucky us, it appears that we're being given that lightweight process with the new Livemarks functionality in Firefox 1.0. In the interim, we should be able to piggyback on this feature, giving users access to automatic feed discovery.
September 15, 2004 @ 7:27 PM | Permalink | Category: Technology | Comments (0)
Sage building steam
Things are really starting to move at the Sage Project. We're getting thousands of downloads a day, multiple code/locale contributions a week, and I'm losing the battle against my ever growing inbox. Good thing I've found a few generous souls to give me a hand.
September 10, 2004 @ 9:43 PM | Permalink | Category: Technology | Comments (0)
Tim Bray tries Sage
Tim Bray took Sage for a spin and gives us a little review. Wait a few months Tim, we'll give you a reason to switch. Maybe it's time we got that OPML import working...
July 15, 2004 @ 8:22 PM | Permalink | Category: Technology | Comments (0)
Sage in Wired News
Sage gets some big media coverage in a Wired News article on Mozilla extensions. It's good to see the platform side of Firefox getting some attention.
July 14, 2004 @ 2:40 PM | Permalink | Category: Technology | Comments (0)